
字符编码笔记
我们知道,计算机是二进制存储的,所有的内容,在计算机内存储下来的都是 0 和 1 来表示的二进制数字。
早期的计算机在设计时,采用 8 个二进制位 (bit) 作为一个字节 (byte),因为每个二进制位都有 0 和 1 两种状态,所以一个字节一共可以表示 28 = 256 种状态。
字符集和字符编码
字符集,从字面上来拆解,其实就是字符的集合;就是把我们使用到的字符整合在一起,并为每一个符号指定一个唯一的编号(叫作 码点)。
因为计算机只能处理二进制数字,那么如果要处理文本内容时,就需要先把文本转换成数字;
将字符集中每一个字符唯一的编号,按照某种规则映射到二进制存储,这就是所谓的 字符编码。
比如最早给英文字符、数字、标点符号等制定了一套编码的 ASCII(American Standard Code for Information Interchange, 美国信息交换标准代码)。
简单来说,字符集是一套被分配了唯一编号的字符的集合,而字符编码则是对字符集映射到二进制的一个实现方式。
字符编码的历史演变
ASCII
在 20 世纪 60 年代,美国制定了一套字符编码,对英语字符和二进制之间的关系,做了统一规定,这被称为 ASCII,一直沿用至今。
ASCII 码一共规定了128个字符的编码,比如空格 SPACE 是 32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的一位统一规定为0。
扩展ASCII
对英语来说,ASCII 内这 128 个字符就够用了,但是对欧洲其他一些国家来说,就不够用了;比如法国、德国等。
然后这些国家就对 ASCII 码做了扩展,利用字节中闲置的最高位编入新的符号,比如法语中的é的编码为130(二进制10000010),如此一来,这些欧洲国家就多出了128个字符可以存储;扩展后的 ASCII 码最多可以表示 256 个字符。
这些扩展编码中,比较流行的编码有 latin-1, ISO-8859-1 等。
可这里也有一个问题:不同的国家有不同的字母,那么不同的扩展,势必会有同一个码点却代表不同的字母这样的情况出现。
其他编码
上面说的只是欧洲这种以字母为主的语种国家,而像我们中国、日本等东亚语系的国家,需要使用的语言符号更多,只用一个字节,根本不够,如此就需要使用多个字节来表示一个字符。比如简体中文 GB2312 编码,就是使用两个字节表示一个汉字,所以理论上最多可以表示出 256 * 256 = 65536 个汉字。
乱码
每个国家都有一套自己的编码方式,尤其是码点在 128-255 之间的字符,每套编码代表的字符都不一样;
如果将一个以A编码方式存储的文件,以B编码方式打开,就会出现乱码的问题。
Unicode
如上所说,世界上存在很多编码方式,同一个二进制数字可以被解释成不同的字符;因此,要想正常打开一个文本文件,就必须知道它的编码方式,否则就会出现乱码。
可以想象,如果存在一种编码,将世界上所有的字符都纳入其中;每个字符都有一个独一无二的码点,大家都使用这同一套编码,那么乱码问题就会消失。
这就是 Unicode 字符集。
UCS与Unicode
人们开始迫切的需要一套统一的字符集,能够包含世界上所有的符号。
1988 年成立的 Unicode 团队和 1989 年成立的 UCS 团队,这两个团队就是想要搞出一套统一字符集成立的。
只是一开始他们并不知道彼此的存在。
1990 年,开发进度较快的 UCS 团队公布了第一套编码方法 UCS-2,使用2个字节表示已有码点的字符,同时这也是 JavaScript 中使用的编码方式。
而等到两个团队发现了对方存在之后,很快达成一致:世界上不需要两套统一字符集。在 1991 年 10 月,两个团队决定合并字符集;以后只发布一套字符集,就是 Unicode;并修复此前发布的字符集,使 UCS 的码点与 Unicode 完全一致。
也由于
JavaScript使用的是UCS-2编码,所以JavaScript的字符处理是有一些问题的,遇到4字节字符时,会当成两个2字节的字符来处理。
即使 ECMAScript6 扩展增强了Unicode的支持,基本解决了这个问题,但是为了兼容性,一些问题还是被保留了下来。
比如"𝓂".length === 2。
不过因为时间上的原因,JavaScript也只能选择UCS-2,而不是现在支持的UTF-16。JavaScript诞生于 1995年5月,Brendan Eich 用了 10 天设计了这套语言;同年10月,第一个解释引擎问世;
而UTF-16的发布时间却是在 1996年7月。
Unicode与UTF
需要注意的是,Unicode 只是一个字符集,它只规定了符号的二进制代码,却没有规定这个二进制代码如何存储。
也就是说有许多中不同的二进制格式,可以用来表示 Unicode。
直到互联网普及,出现了几种使用较为广泛的编码方式,其中就有我们现在常用的 UTF-8,其他还有 UTF-16 和 UTF-32。UTF 的全称是 Unicode/UCS Transformation Format,亦即把 Unicode 字符转换为某种格式。
平面
Unicode 的编码空间从 U+0000 到 U+10FFFF,一共有 1,112,064 个码点可以用来映射字符。
这么多字符,Unicode 也并不是一次性定义的,而是分区定义的。
每个区可以存放 65536 个字符(16位,216),这样一个分区称为一个“平面”。
而目前一共有 17 个平面,也就是说,整个 Unicode 字符集的大小是 221。
在这 17 个平面里,前 65536 个字符,也就是第一个平面,也被称为基本平面(Basic Multilingual Plane,基本多语言平面, BMP),其他平面称为辅助平面(Supplementary Planes)。
你可能偷偷计算了一下,发现 221 远大于上面说的 1,112,064 个码点。
其实在这 221 个码点里,并不是每个码点都用来映射字符。
在基本平面内,从 U+D800 到 U+DFFF 之间的码点区段是永久保留不映射到 Unicode 字符的;
而辅助平面码点的编码就是利用这个区段的码点来进行的。
UTF-32
这个仅了解一些就好,因为实际上很少会使用这个编码,甚至HTML5标准中明文规定,禁止支持 UTF-32 编码。
UTF-32 的编解码规则简单,所有字符都用四个字节表示,并完全对应 Unicode 码点,查找效率很高;但是它的缺点是很浪费空间,如果是纯英文文本,UTF-32 编码的占用空间是 ASCII 编码的四倍,在以前那个空间并不充足的年代,这几乎是无法容忍的;即使是现在,这也是一个致命的缺点。
https://html.spec.whatwg.org/#character-encodings
Note
The above prohibits supporting, for example, CESU-8, UTF-7, BOCU-1, SCSU, EBCDIC, and UTF-32. This specification does not make any attempt to support prohibited encodings in its algorithms; support and use of prohibited encodings would thus lead to unexpected behavior.
UTF-16
UTF-16 可以说是 UCS-2 的一个扩展,基本平面内的字符使用 2 个字节表示,辅助平面的字符使用 4 个字节表示。
| Unicode 码点 | UTF-16 编码 | 注释 |
|---|---|---|
U+0000 - U+D7FF, U+E000 - U+FFFF |
xxxxxxxx xxxxxxxx |
基本平面内,使用两个字节表示,U+D800 - U+DFFF 是保留区段 |
U+010000 - U+10FFFF |
110110xx xxxxxxxx 110111yy yyyyyyyy |
辅助平面,使用四个字节表示,并有前缀标识 |
从U+D800到U+DFFF
Unicode 标准规定从 U+D800 到 U+DFFF 的码点不对应任何字符。
但是在使用 UCS-2 的时代,这些码点是有对应字符的。因此,只要不构成代理对,许多 UTF-16 编码解码还是会把这些不符合 Unicode 标准的字符映射正确的辨识并转换成合规的码元。
但是按照 Unicode 标准来说,这种码元序列本来应该算作是编码错误。
代理对与UTF-16辅助平面编码方式
Unicode 辅助平面中码点,在 UTF-16 中被编码为一对16bit的码元(即32位,4字节),称作代理对(Surrogate Pair)。
具体方法是:
- 码点减去
0x10000,得到的值的范围为 20 比特长的0...0xFFFFF。 - 高位的 10 比特的值(范围为
0...0x3FF)被加上0xD800得到第一个码元,称作高位代理(high surrogate),新值的范围是0xD800...0xDBFF。【由于高位代理比低位代理的值要小,为了避免混淆使用,Unicode标准现在称高位代理为前导代理(lead surrogate) - 低位的 10 比特的值(范围也是
0...0x3FF)被加上0xDC00得到第二个码元,称作低位代理(low surrogate),新值的范围是0xDC00...0xDFFF。【由于低位代理比高位代理的值要大,为了避免混淆使用,Unicode标准现在成低位代理为后尾代理(trail surrogate)
上述算法可以这样理解:
辅助平面中的码点范围是 U+010000 到 U+10FFFF,共计 0xFFFFF 个,即 220个,也就是需要 20 个二进制位来表示。
如果用两个 16 位长的整数组成的序列来表示,第一个整数(即前导代理)要容纳 20 位中的前 10 位,第二个整数(即后尾代理)容纳 20 位中的后 10 位。
因为 UTF-16 基本平面的字符就是由一个 16 位长的整数表示的,这里的两个 16 位整数序列就需要一个区分标识。
一是与基本平面码点的区分,二是前导代理与后尾代理的区分。
与基本平面码点的区分,就来自于之前讲的 Unicode 保留区段 U+D800...U+DFFF,因为两个整数中只容纳了 20 位中的 10 位二进制数字,也就是最大只有 0x3FF,那么就可以通过给这两个整数增加一个固定数字,使其位于 U+D800...U+DFFF 这个区段内,就可以与基本平面的码点区分开来。
前导代理与后尾代理的区分,则通过增加不同的数字,使二者落入 U+D800...U+DFFF 区段的不同部分来区分。
你会发现,U+D800...U+DFFF 的区间长度是 2047,0x3FF 的十进制是 1023,刚好是区段一半的大小;
那么以区段的初始值 U+D800 和中间值 U+DC00 分别作为前导代理和后尾代理增加的值,就可以刚好将两个值分别放入 U+D800...U+DFFF 区间的前半段 U+D800...U+DBFF 和后半段 U+DC00...U+DFFF。
所以,UTF-16 遇到两个字节,码点位于 U+D800...U+DBFF 之间时,就可以断定,后续的两个字节码点位于 U+DC00...U+DFFF 之间,并将这四个字节一起解读为一个字符。
UTF-8
UTF-16 编码是一个很不错的编码方式,因为大部分常用字符都位于基本平面内,也就是使用2字节就可以表示大部分的常用字符。
可是也同样是因为使用 2 个字节存储,导致它不能兼容 ASCII 编码。
而 UTF-8 就是一种可以兼容 ASCII 编码的变长的 Unicode 的编码实现。
UTF-8 是一种针对 Unicode 的可变长度字符编码,也是一种前缀码。
它可以用一至四个字节对 Unicode 字符集中的所有有效编码码点进行编码。
由于较小值的编码点一般使用频率较高,直接使用 Unicode 编码【此处指UTF-32编码】效率低下,大量浪费内存空间。UTF-8 就是为了解决向后兼容 ASCII 码而设计的, Unicode 中前 128 个字符,使用与 ASCII 码相同的二进制值的单个字节进行编码,这使得原来处理 ASCII 字符的软件无需或只需做少部分修改,即可继续使用。
也因此,它逐渐成为电子邮件、网页及其他存储或发送文字优先采用的编码方式。
实现方式
| Unicode 码点 | UTF-8 编码 | 注释 |
|---|---|---|
U+0000 - U+007F |
0xxxxxxx |
ASCII 字符范围,单字节,字节由 0 开始 |
U+0080 - U+07FF |
110xxxxx 10yyyyyy |
双字节字符,第一个字节由 110 开始,后续字节由 10 开始 |
U+0800 - U+D7FF, U+E000 - U+FFFF |
1110xxxx 10yyyyyy 10zzzzzz |
三字节字符,第一个字节由 1110 开始,后续字节由 10 开始 |
U+010000 - U+10FFFF |
11110xxx 10yyyyyy 10zzzzzz 10wwwwww |
四字节字符,第一个字节由 11110 开始,后续字节由 10 开始 |
从上面的表格中,你应该能够直观的看出来,在 UTF-8 编码中,从一个字节开始的二进制位,就能判断出这个字节的大致位置。
- 如果字节以
0开始,那么它单独表示一个ASCII字符 - 如果字节以
10开始,那么它是一个多字节字符的非首字节 - 如果字节以
110开始,那么它是一个二字节字符的首字节,且后续会有一个以10开头的字节 - 如果字节以
1110开始,那么它是一个三字节字符的首字节,且后续会有两个以10开头的字节 - 如果字节以
11110开始,那么它是一个四字节字符的首字节,且后续会有三个以10开头的字节
可以很明显的看到,除了前面 128 个字符,跟 ASCII 码保持相同之外,UTF-8 的多字节字符,首字节起始的连续的 1 的数量就是它所占用的字节数,后续字节之所以用 10 开头,也是为了与单字节做区分,避免混淆。
那么 UTF-8 具体是怎么编码的呢?
- 查看字符在
Unicode的码点所处区间,来确定字节数U+0000至U+007F一个字节U+0080至U+07FF两个字节U+0800至U+FFFF三个字节U+010000至U+10FFFF(即16个辅助平面)四个字符
- 如果是一个字节,直接使用码点对应的8位二进制码
- 如果是多字节,那么将码点对应的二进制码,从右到左,一个个填充到上面表格对应字节中的待填充区域【就是表格里的
x,y,z,w的位置】,待右侧填充完毕,如果左侧还有未填充的位置,则统一填 0,就得到了UTF-8中对应的二进制码。
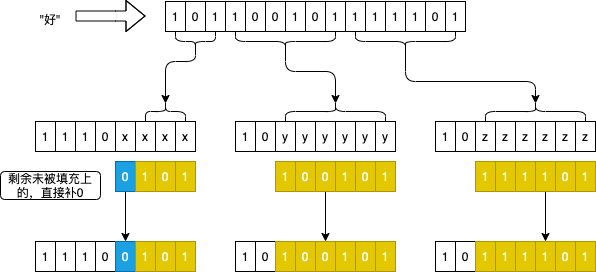
比如:好 在 Unicode 中的码点是十六进制的 0x597D,落在区间 U+0800 - U+FFFF 内,所以在 UTF-8 中表示是三字节:1110xxxx 10yyyyyy 10zzzzzz。0x597D 转成二进制表示是 0b101100101111101,然后从右向左填充,切出最右边的6位 111101 填入第三个字节右侧 6 个 z 的位置,再切出余下的右侧 6 位 100101 填入第二个字节右侧 6 个 y 的位置,余下 3 位 101 填入首字节的最右侧,最后还有一个 x 未填充,补上 0,就得到了 好 字在 UTF-8 中的二进制码 11100101 10100101 10111101。
参考链接
https://blog.csdn.net/yaomingyang/article/details/79374209
http://www.ruanyifeng.com/blog/2014/12/unicode.html
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
https://www.jianshu.com/p/0f5fd93efc46
https://www.liaoxuefeng.com/wiki/1016959663602400/1017075323632896
https://www.codenong.com/10611455/
https://zhaoji.wang/javascript-note-1-character-encoding/
https://zh.wikipedia.org/wiki/UTF-16
https://zh.wikipedia.org/wiki/UTF-8
https://zhuanlan.zhihu.com/p/51202412